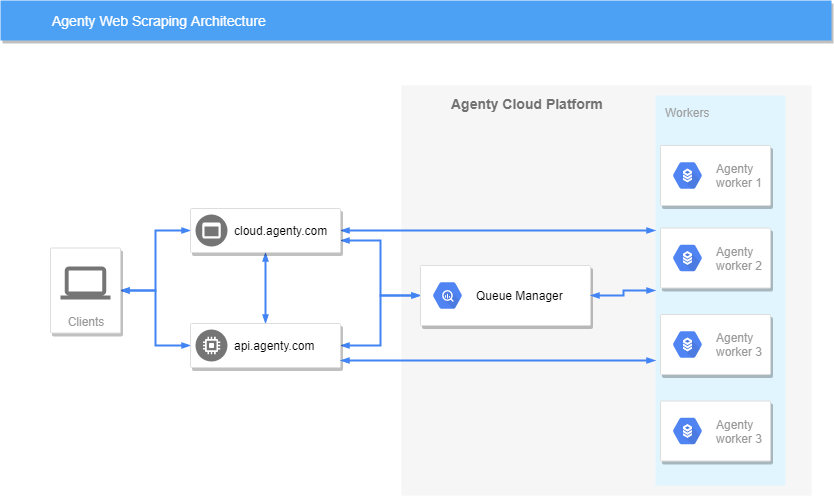
Agenty web scraping API is an asynchronous API and handles automatic proxy rotation, headless browsers, captcha with advanced configuration like pagination, fail-retries and login to extract any number of fields. Let’s see how to manage data using web scraping API.
You can use CSS selectors, Regex and JSON to configure fields in your scraper to scrape anything from web-pages. If you are a pro user like Data Scientists or Developers? who usually needs to modify or clean the web data to ingest in their machine learning and AI algorithms can use the built-in post-processing functions or scripting to modify the web scraped data along with scraping data anonymously from any website.
Here are some C# examples to manage a custom web scraping agent using Agenty API. In this example, I am using popular RestSharp open-source library available on Github and Nuget to install on .net project to showcase how to create scraper, start the web scraping job and then download the output in C# and Microsoft .NET framework.
If you are in hurry and want to see the code first, check out this open-source Github reporstority I created for this article - https://github.com/vickyrathee/Web-Scraping-API/ to clone and try your own custom web scraping project with Agenty.
I am using 2 Nuget packages in this project.
- RestSharp
- Newtonsoft.Json
To install the nuget package in your project, you can run the Install-Package command in Visual Studio by clicking on the Tools > Nuget Package Manager > Package Manager Console
Install-Package RestSharp
Create Web Scraper
We recommend initially creating a scraper using our Chrome extension available on the Chrome store. And then you can add or change anything in the scraping agent configuration using the API or our scraping agent editor which available at cloud.agenty.com.
So, I will skip the creating of scraper part in this article to focus more on scraping websites via API. But, If you are new to Agenty’ web scraping tools? See this tutorial to learn how to create a web scraper.
Add URLs to Web Scraper
This API will send a HTTP PUT request with a data array to add/update URLs to a scraper. Maximum 25,000 URL per request, and If you have more? use the list API to upload and then attach the list using the reference option.
Code
using RestSharp;
void Main()
{
string apiKey = "your api key here";
string agentId = "your agent id here";
var client = new RestClient($"https://api.agenty.com/v1/inputs/{agentId}?apikey={apiKey}");
var request = new RestRequest(Method.PUT);
List<string> urls = new List<string>();
urls.Add("http://domain.com/category/");
urls.Add("http://domain.com/category/page-1.html");
urls.Add("http://domain.com/category/page-2.html");
var requestBody = new { type = "MANUAL", data = urls.ToArray() };
request.AddJsonBody(requestBody);
request.AddHeader("Content-type", "application/json");
IRestResponse response = client.Execute(request);
Console.WriteLine(response.Content);
}
Response
{
"status_code":200,
"message":"3 manual input updated successfully"
}
Start Web Scraping Job
This API will send a HTTP POST request with agent_id in the request body, to start a new web scraping job. The web scraping job will be sent to Agenty workers to process asynchronously.
You’d be able to get the job_id in response to track this web scraping job status and also download the result when it’s completed.
Code
using RestSharp;
void Main()
{
string apiKey = "your api key here";
string agentId = "your agent id here";
var client = new RestClient($"https://api.agenty.com/v1/jobs/scraping/async?apikey={apiKey}");
var request = new RestRequest(Method.POST);
var requestBody = new { agent_id = agentId};
request.AddJsonBody(requestBody);
request.AddHeader("Content-type", "application/json");
IRestResponse response = client.Execute(request);
Console.Write(response.Content);
}
Response
{
"status_code":200,
"message":"A new scraping job 113362 submitted successfully",
"job_id":113362
}
Check Web Scraping Job Status
This API will send a HTTP GET request to check the status of a scraping job to see if the job has been completed or not. We can also see the additional parameters in response like pages_processed to get an idea how many web-pages has been scraped; and how many remain to be processed in the list.
We recommend using our webhook or S3 plugin for automatic data transfer to your server instead of waiting and continuously checking the status of the web scraping job on loop.
But, if you are still using this status API for some reason - Use the Thread.Sleep(2500) or Task.Delay(2500) for async method to add a few seconds delay in your code while checking the web scraping job status in a loop.
Code
using RestSharp;
void Main()
{
string apiKey = "your api key here";
string jobId = "your job id here";
var client = new RestClient($"https://api.agenty.com/v1/jobs/{jobId}?apikey={apiKey}");
var request = new RestRequest(Method.GET);
request.AddHeader("Content-type", "application/json");
IRestResponse response = client.Execute(request);
Console.Write(response.Content);
}
Response
{
"job_id":113362,
"agent_id":"m0vjql990v",
"type":"scraping",
"status":"completed",
"pages_total":2,
"pages_processed":2,
"pages_successed":2,
"pages_failed":0,
"pages_credit":2,
"created_at":"2019-08-12T05:53:13",
"started_at":"2019-08-12T05:53:16",
"completed_at":null,
"stopped_at":null,
"is_scheduled":false,
"error":null
}
| Property | Data Type | Description |
|---|---|---|
| job_id | number |
The unique id of this web scraping job |
| agent_id | string |
The web scraping agent id for which this job is started |
| type | string |
Type of agent : scraping
|
| status | string |
The status of job : running, queued, completed etc |
| pages_total | number |
Number of total inputs this scraping agent is running for |
| pages_processed | number |
Number of pages processed in this web scraping job |
| pages_successed | number |
Number of pages success-ed in this web scraping job: (2xx) |
| pages_failed | number |
Number of pages failed in this web scraping job (4xx, 5xx) |
| pages_credit | number |
Number of pages credit consumed by this web scraping job |
| created_at | datetime |
The UTC time when this web scraping job was created by API |
| started_at | datetime |
The UTC time when this web scraping job was started by Agenty workers |
| completed_at | datetime |
The UTC time when this web scraping job was completed |
| stopped_at | datetime |
The UTC time of stop request, if the scraping job is stopped by user |
| is_scheduled | bool |
True of False: If this web scraping job is started by Agenty scheduler then true, otherwise false
|
| error | string |
Error message, if this web scraping job completed with any error. |
Download Web Scraping Job Result
This API will fetch the result of your web scraping job in streaming JSON format. We can send a HTTP GET request to this API with the job_id from the previous response to fetch the result.
The streaming jobs API will fetch a maximum 2500 rows per request. If you have more rows in your web scraping result using the offset and limit query parameter to paginate and download all results using loop.
For example, if you have 10000 rows in your web scraping job result - just keep increasing the offset variable by 2500 in this example code using a for loop.
- offset = 0
- offset = 2500
- offset = 5000
- offset = 7500 and so on…
Code
using RestSharp;
void Main()
{
string apiKey = "your api key here";
string jobId = "your job id here";
int offset = 0;
int limit = 2500;
var client = new RestClient($"https://api.agenty.com/v1/jobs/{jobId}/result?apikey={apiKey}&offset={offset}&limit={limit}");
var request = new RestRequest(Method.GET);
request.AddHeader("Content-type", "application/json");
IRestResponse response = client.Execute(request);
Console.Write(response.Content);
}
Response
{
"total":2,
"limit":2500,
"offset":0,
"returned":2,
"result":[
{
"name":"Tony Hunfinger T-Shirt New York - Black",
"price":"$800.00"
},
{
"name":"Tony Hunfinger T-Shirt New York - White",
"price":"$800.00"
}
]
}
This article code will be found here - https://github.com/vickyrathee/Web-Scraping-API/