Agenty CSS Selector and REGEX extractor engine can be used to extract anything from the website content, but sometime you might want few fields to be included in your output result which is not the part of website source content.
For example you are scraping stock information of 100 companies from a stock website but also want a DateTime field should also be in your output result to see when a particular page was fetched and information was extracted.
So Agenty offers the built-in default fields to add in your agent for all those cases when needed :
How to add a DEFAULT Field
- Click on the Configuration tab to edit your agent in agent editor (Create one using Chrome extension if you don’t have any agent, the DEFAULT fields can be added after the agent is created)
- Then go to Field and Collections section and click on Add field button to add a field
- Change the Type as DEFAULT
- Select the system field you want to add in From drop-down box as in screenshot below:
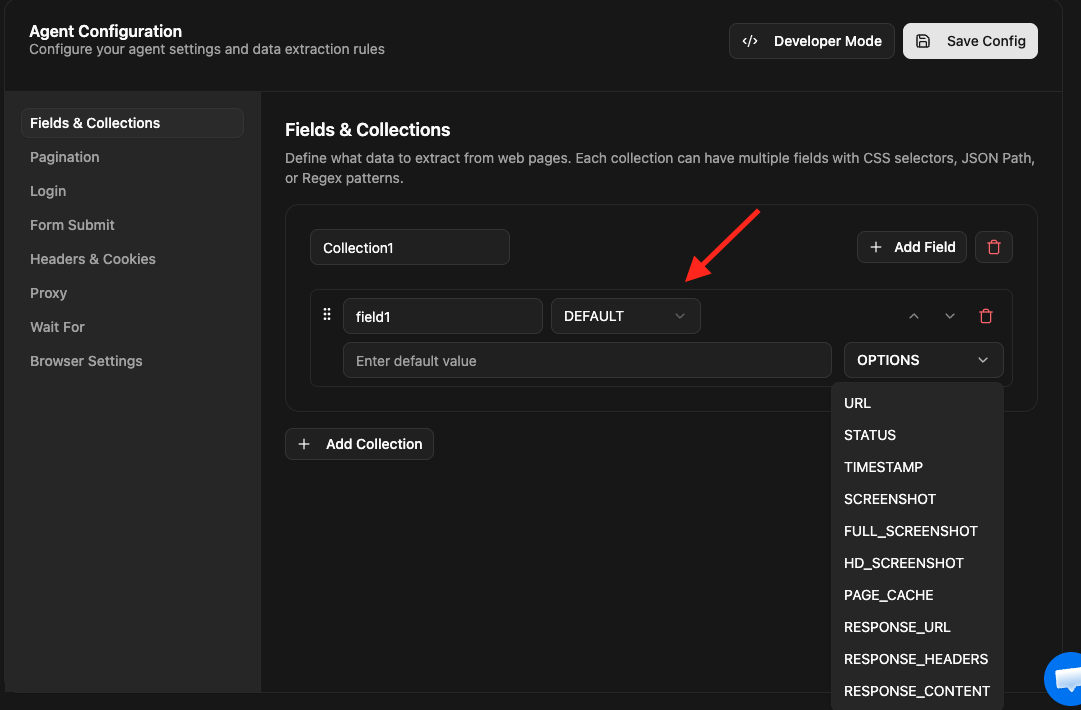
- Finally, Save the scraping agent configuration.
These steps will change the scraping agent configuration only and you’d need to re-run your agent to extract the default field value when the field is added or updated.
Default value
DateType: string
To add constant value in the data scraping output, we can just enter the text in From field with the combination of default field types.
For example, If I want to add a “Category” field with constant value as “Mobile” to display in my output, this is how it should looks like in fields configuration -
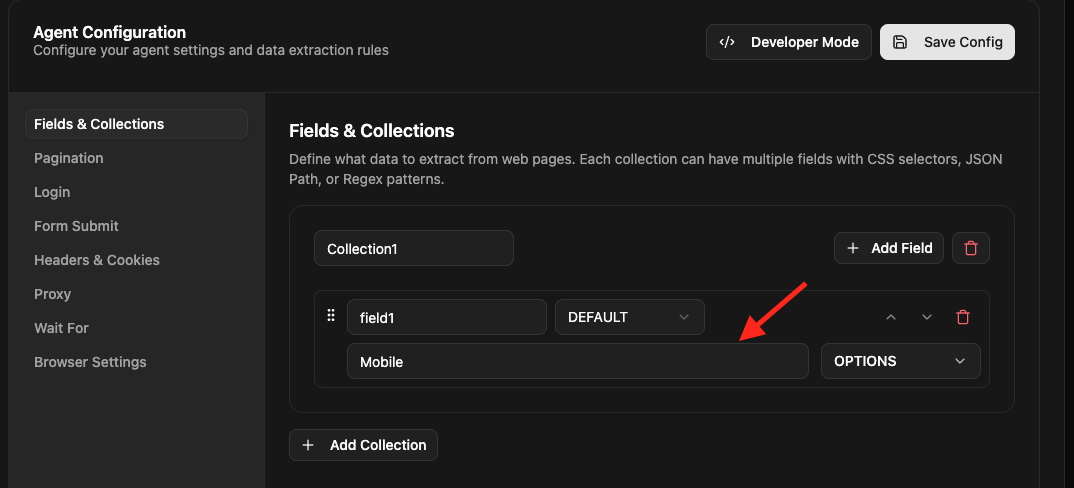
URL
DateType: string
URL of web page, same as in provided in input
RESPONSE_URL
DateType: string
URL of web page returned by web server even after redirects.
(E.g. If your inputs have old URL http://www.domain.com/some-old-product-page.html but web server returns a 301 redirect and serves the new URL http://www.domain.com/new-page.html. The RESPONSE_URL field will have the new URL populated)
STATUS
DateType: string
HTTP Status of successful web request (E.g. Ok, Moved Permanently)
RESPONSE_HEADER`
DateType: string
Collection of web response Header. E.g.
Cache-Control:private
Connection:Keep-Alive
Content-Encoding:gzip
Content-Length:8922
Content-Type:text/html; charset=utf-8
Date:Thu, 10 Dec 2015 11:44:36 GMT
Proxy-Connection:Keep-Alive
Server:Microsoft-IIS/7.5
Vary:Accept-Encoding
X-AspNet-Version:4.0.30319
X-Powered-By:ASP.NET
RESPONSE_CONTENT
DateType: string
Complete source code of requested web page
<!DOCTYPE html>
<html>
<head>
<title>Sample page</title>
</head>
<body>
<h1>Page Heading</h1>
<h2>This is an example page</h2>
.....
.....
.....
</body>
</html>
TIMESTAMP
DateType: DateTime
The date time when a particular request was fetched (Format : MM/dd/yyyy hh:mm:ss) in GMT (UTC +0) with no offset from Coordinated Universal Time (UTC)