Using Agenty, we can extract details page data from a list page. As most of the websites display the search/list page to explore their products, when we search for something or browse by category. But those listed items don’t have much information and we may need to click on each item to grab further product details by click-through. So, it’s very important for a web scraper to have such a feature, to automate the data scraping of details page from list page.
Agenty scraping agents have a tremendously useful feature called Connecting scraping agents which uses the URL from source agent option in input to connect multiple agents. So we can use this feature for list-details page scraping automatically. In order to automate this task, we’d need to create 2 agents . Let’s learn how to scrape lists and detailed pages:)
https://www.youtube.com/watch?v=C3YcxTErOD8
-
1st scraping agent for list page : This agent will traverse to category/search page and will extract the basic details(if available) and the details page URL, let’s assume we named it
DETAILS_PAGE_URL -
2nd scraping agent for details page : Now we need to create a 2nd agent to extract the information from the details page. We can use any example details page link to setup our agent and add as many fields as needed. Then, once the agent is created, we will change it’s input type as URL from source agent by selecting our 1st agent in input, and then point it to the field which has the URL, for example
DETAILS_PAGE_URL
By this way, we can connect as many agents as needed, to go to any deep level of a website. Here is the detailed example :
List Scraping Agent
-
Go to the website list/search page URL.
-
Open the Agenty Chrome extension and setup fields.
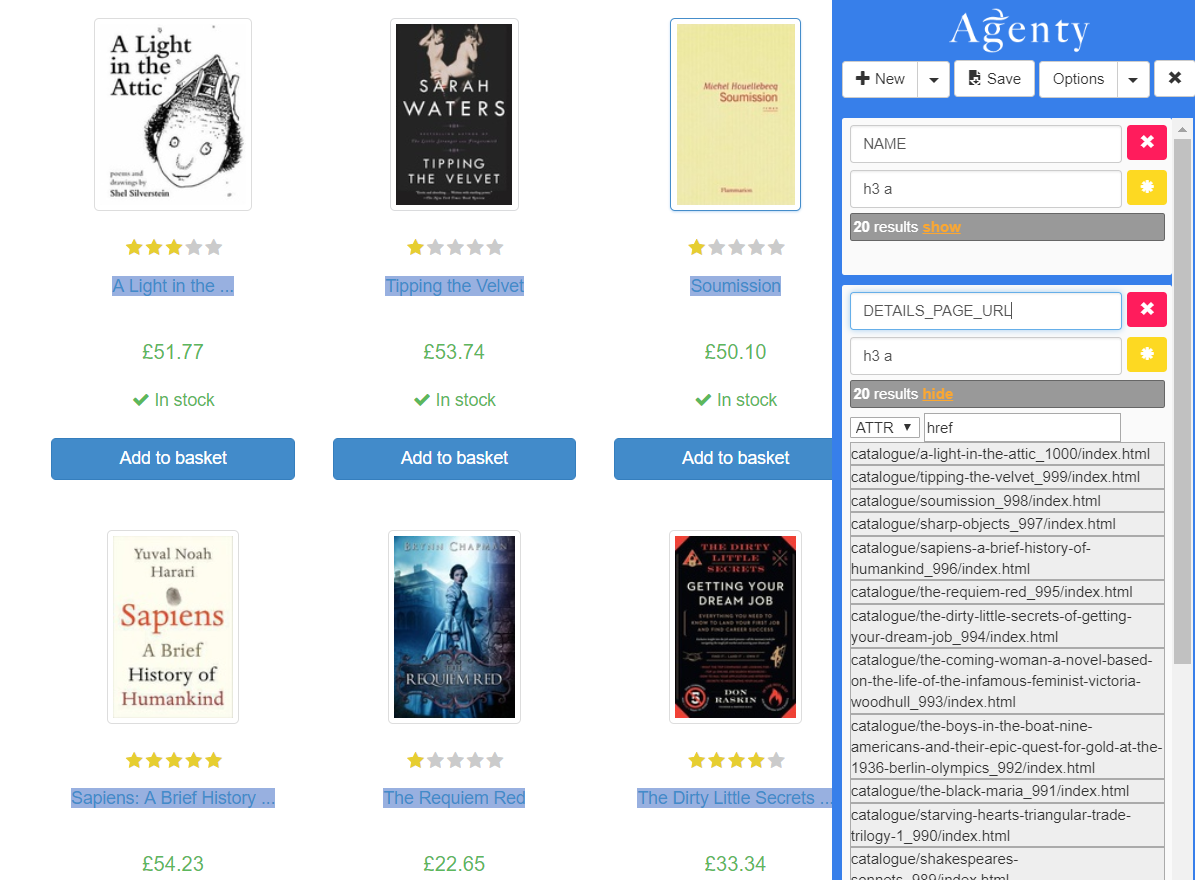
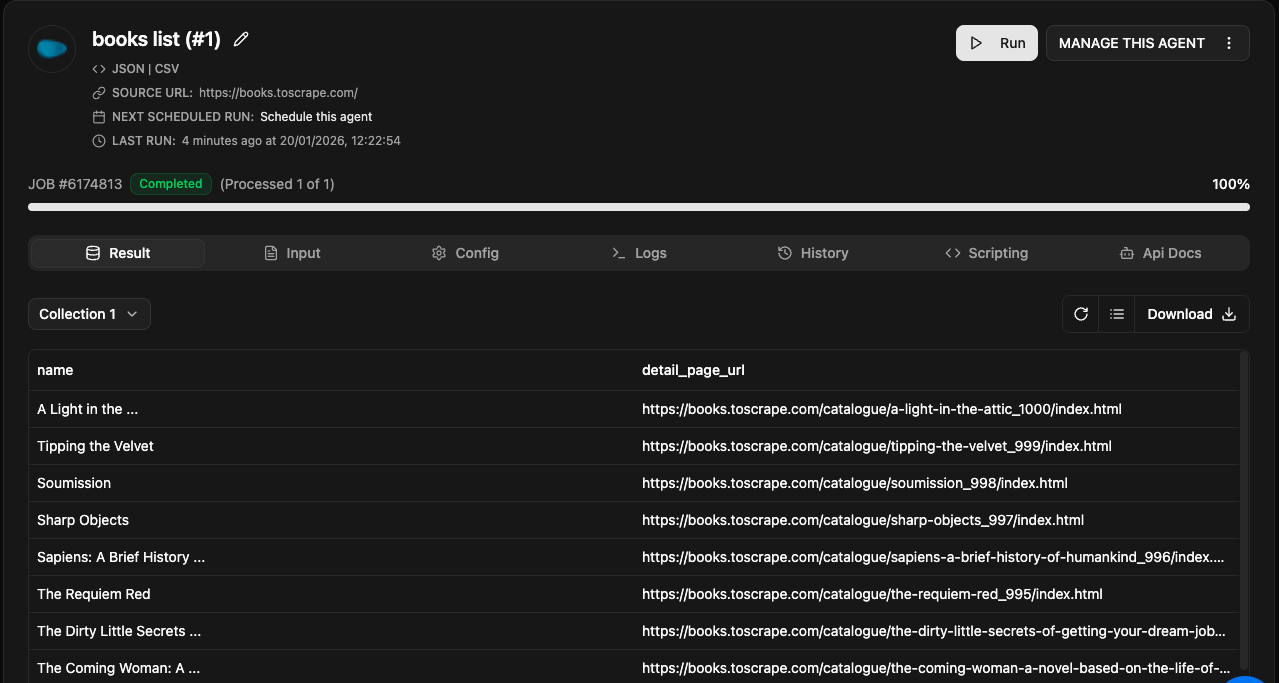
- Let’s Save the scraping agent first, and it will run automatically
Remember, we just need the
DETAILS_PAGE_URLin our 1st agent and other fields are optional.
Details Scraping Agent
If you’ve reached here by following the steps, we have created our 1st agent to extract the data from the website list page. And ready to make our 2nd agent which will extract the detail page from each listing, by connecting both agents and URL from source agent option in input type. Let’s create the 2nd agent :
Steps
-
Go to any example details page URL from the list #1
-
Open the Agenty extension and setup all the fields you want to included in your 2nd agent of details page scraping
-
Save the agent (The agent will auto-execute using default input type :
SOURCE URLwhen saved in Agenty cloud)
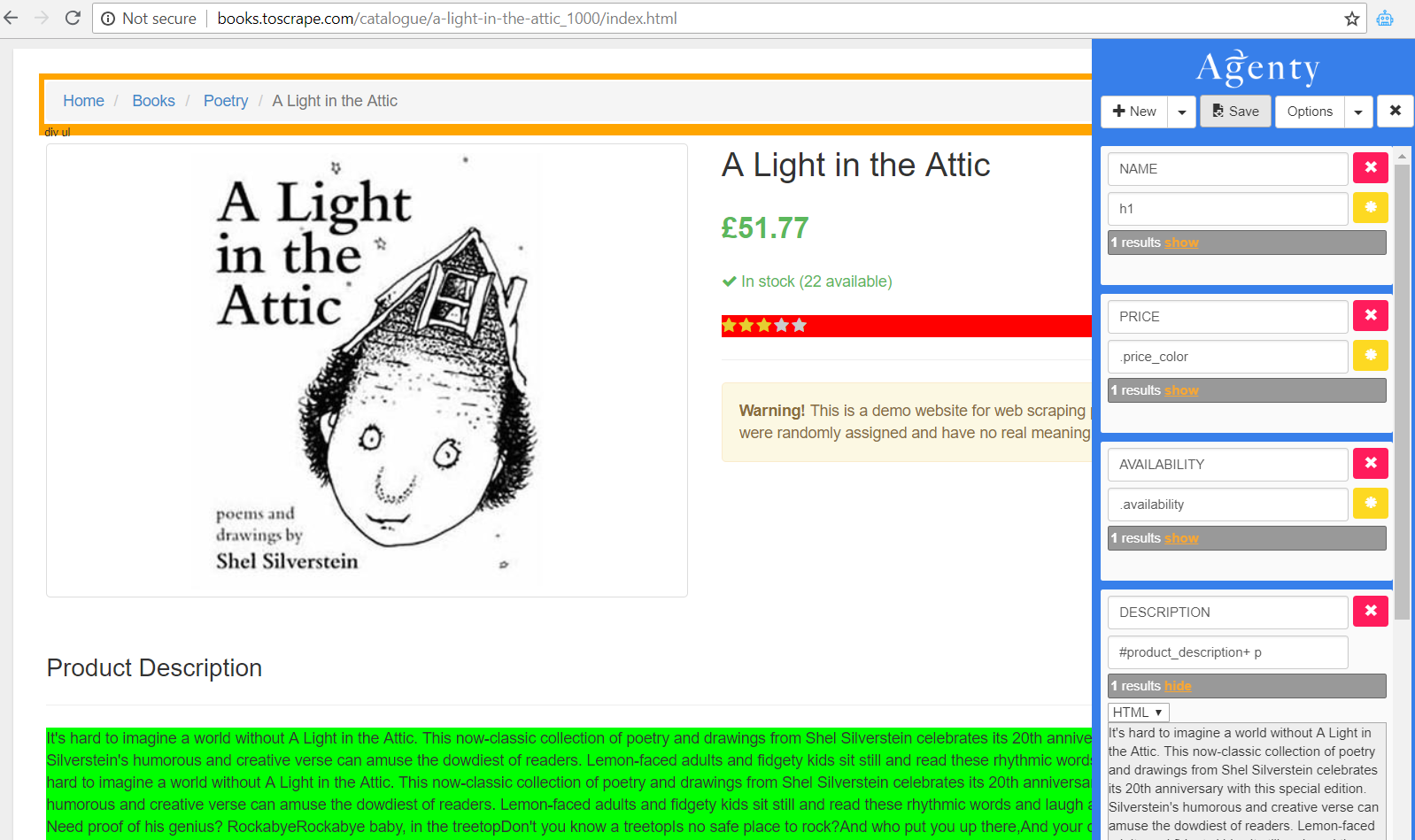
- Now, we need to change it’s input type as
URL from source agentto point the agent to ourbooks list #1agent. That way, the 1st agent output will be considered as 2nd agent input and this agent will grab theDETAILS_PAGE_URLfrom the source agent to extract details for each product.
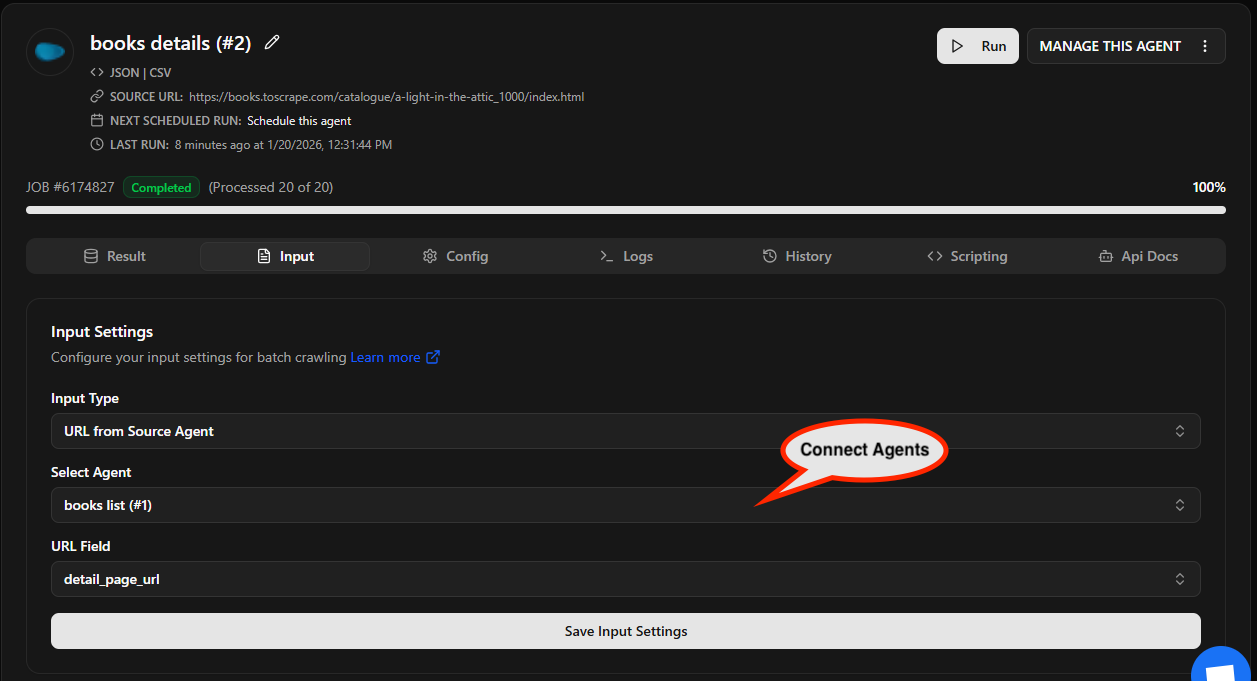
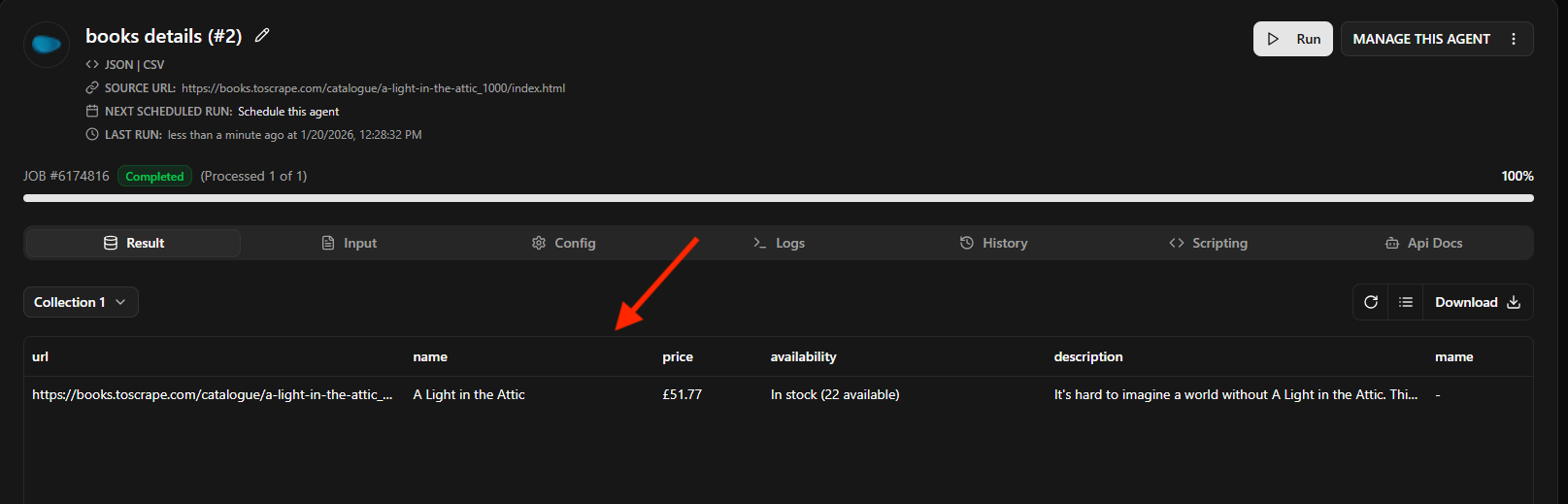
- Now both agents are connected, so we can run the 2nd agent to extract all details page from list
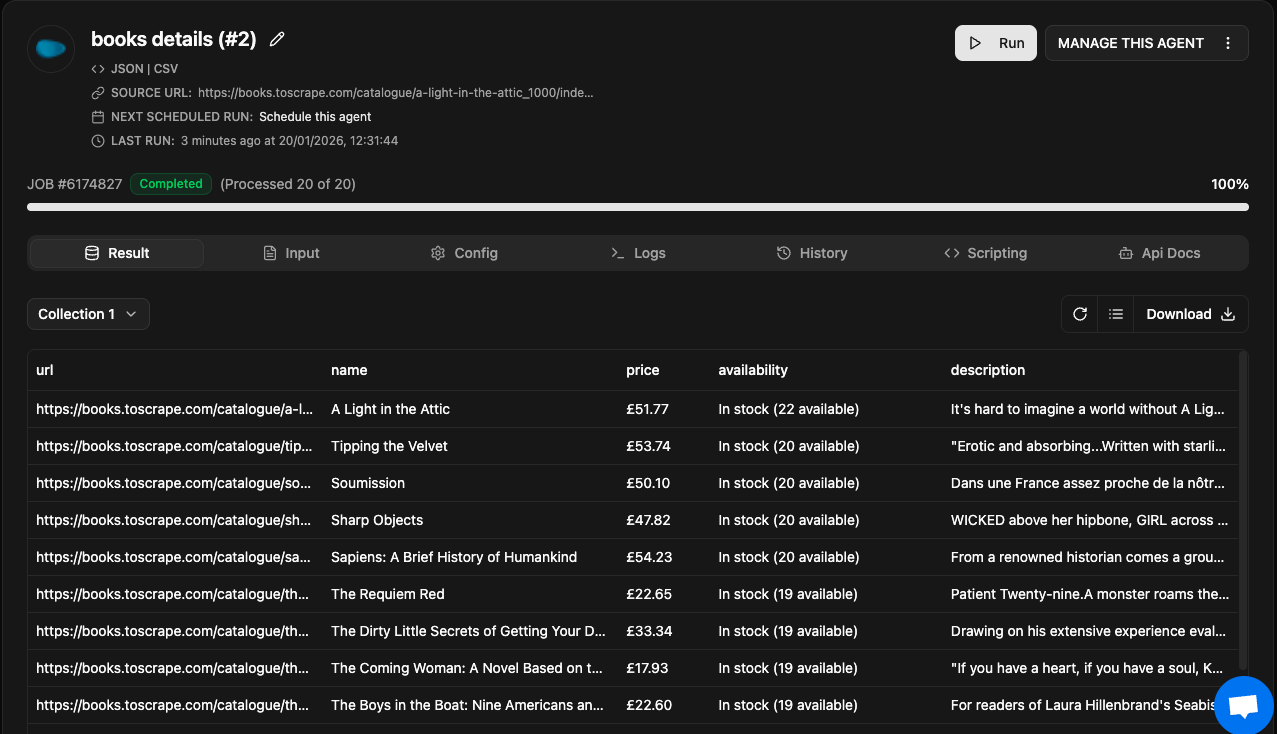
-
If you see the screenshot above, Agenty grabbed all 20 pages from list agent output and then extracted each detail page for (
NAME,PRICE,AVAILABILITYandDESCRIPTION) fields. -
And I also added the default field
REQUEST_URLwith name asPAGE_URLto better analyze my scraped result, as what page returned in what output. You can learn more about adding default fields here.
Scraping More Pages in List
In most cases, you want to extract more than one page in your list scraper from some product categories or search page. So you can follow this pagination tutorial to get all the products list, before extracting the details of each products.
And you can also use the “Start an Agent” Plugin to automatically run the 2nd agent when the 1st agent completes a job and the list is ready to scrape details.