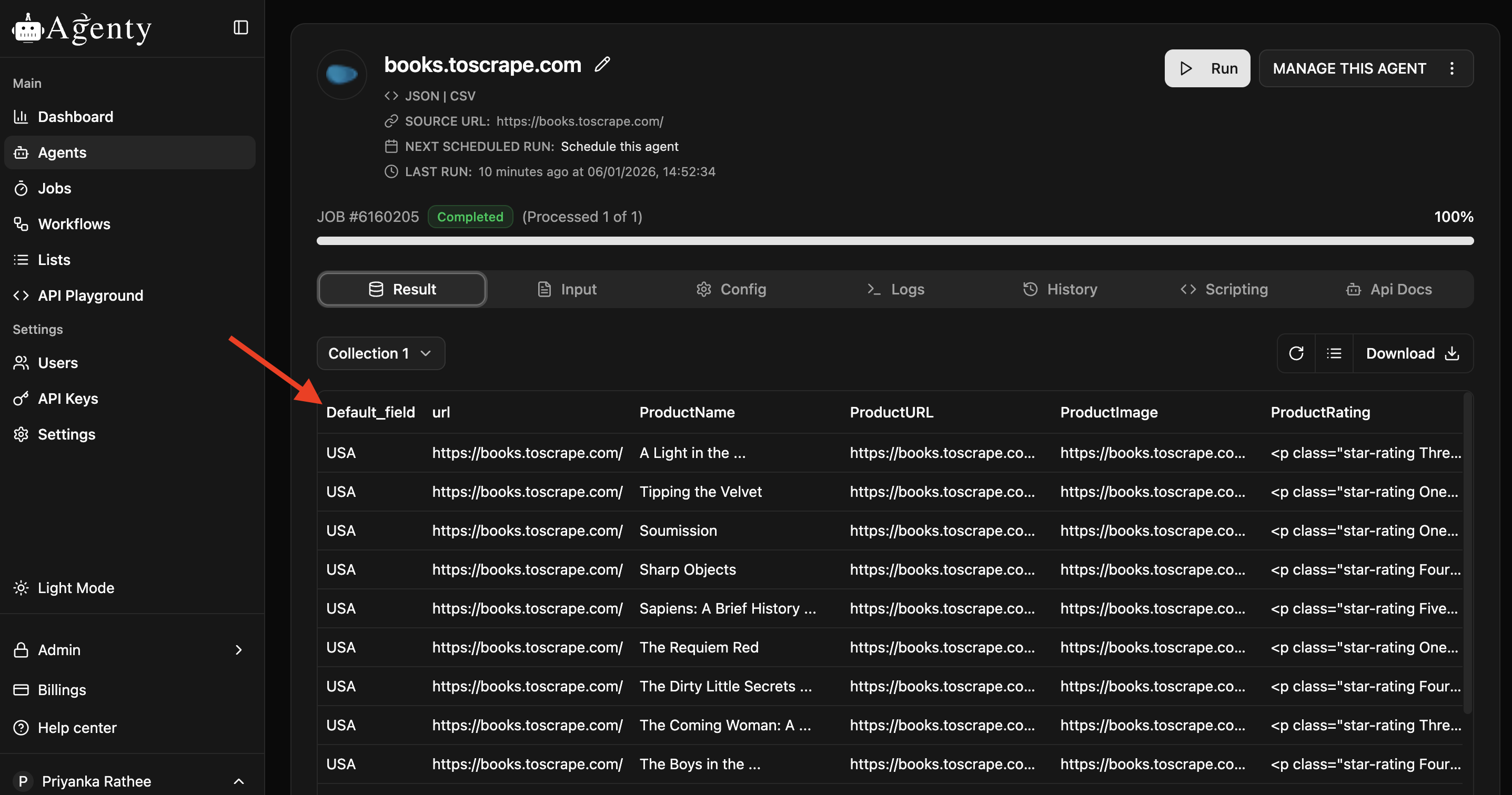
A scraping agent is a set of configurations like fields, selectors, headers etc. for a particular website scraping. The scraping agent can be used to extract data from public websites, password-protected websites, sitemaps, RSS feeds, XML pages, web APIs, JSON pages and many more sources on the web.
The scraping agent can be created using our Chrome extension available on Chrome store
A single scraping agent can extract data from any number of pages, whether it’s 100 or millions of similar structured pages. You just need to supply the URLs using several input types options available in agent or can use advanced features like pagination, password-protected site crawling by supplying the credentials automatically and scripting to clean, validate or manipulate the input or result data:

Most of the websites have their own different HTML structure to display the page content and body, so a single scraping agent can extract the data from a particular website only, where it was set up. But can extract any number of pages with similar structure using pagination or by adding a URL list.
Example Configuration
{
"name": "Books price scraping agent",
"description": "This agent will extract the product list, prices, image and detail page hyperlink from books.toscrape.com website",
"type": "scraping",
"config": {
"sourceurl": "http://books.toscrape.com/",
"collections": [
{
"name": "Collection1",
"fields": [
{
"name": "NAME",
"type": "CSS",
"selector": "h3 a",
"extract": "TEXT",
"attribute": null,
"from": null,
"visible": true,
"cleantrim": true,
"joinresult": false,
"postprocessing": [],
"formatter": []
},
{
"name": "PRICE",
"type": "CSS",
"selector": ".price_color",
"extract": "TEXT",
"attribute": "",
"from": null,
"visible": true,
"cleantrim": true,
"joinresult": false,
"postprocessing": [
{
"function": "Insert",
"parameters": [
{
"name": null,
"value": "http://books.toscrape.com/"
}
]
}
],
"formatter": []
},
{
"name": "IMAGE",
"type": "CSS",
"selector": ".thumbnail",
"extract": "ATTR",
"attribute": "src",
"from": null,
"visible": true,
"cleantrim": true,
"joinresult": false,
"postprocessing": [
{
"function": "Insert",
"parameters": [
{
"name": "Input",
"value": "http://books.toscrape.com/"
}
]
}
],
"formatter": []
},
{
"name": "DETAILS_PAGE_URL",
"type": "CSS",
"selector": ".product_pod h3 a",
"extract": "ATTR",
"attribute": "href",
"from": null,
"visible": true,
"cleantrim": true,
"joinresult": false,
"postprocessing": [
{
"function": "Insert",
"parameters": [
{
"name": "Input",
"value": "http://books.toscrape.com/"
}
]
}
],
"formatter": []
}
]
}
],
"engine": {
"name": "default",
"loadjavascript": true,
"loadimages": false,
"timeout": 30,
"viewport": {
"width": 1280,
"height": 600
}
},
"waitafterpageload": null,
"login": {
"enabled": false,
"type": null,
"data": []
},
"logout": null,
"pagination": {
"enabled": true,
"type": "CLICK",
"selector": ".next a",
"maxpages": 50
},
"header": {
"method": "GET",
"encoding": "utf-8",
"data": [
{
"key": "Accept",
"value": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"
},
{
"key": "User-Agent",
"value": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"
},
{
"key": "Accept-Language",
"value": "*"
}
]
},
"autoredirect": {
"enabled": true,
"maxautoredirect": 3
},
"failretry": {
"enabled": true,
"maxtry": 3,
"tryinterval": 2,
"timeout": 0
},
"proxy": {
"enabled": false,
"type": null,
"reference": null
},
"throttling": {
"enabled": false,
"type": null,
"seconds": 0
},
"formsubmit": {
"enabled": false,
"data": []
},
"meta": null,
"input": {
"type": "SOURCE",
"reference": null
}
}
}
Engine
The engine object is mandatory and indicates the type of web scraping engine (or browser) will be used in the cloud to execute your agent.
-
Default- The
Defaultengine is fast in speed and supports all features to scrape any website. This is selected by default and should be used if you do not know how scraping works. -
FastBrowser-
FastBrowserengine is faster thanDefaultengine but has JavaScript disabled permanently. This engine should be used for any website which does not require JavaScript to be loaded in order to crawl their data. -
HttpClient-
HttpClientengine is super-fast from all other engines. But cannot login, form submit and no JavaScript support. This engine can be used to scrape static websites, XML, web API, JSON pages etc.
"engine": {
"name": "default",
"loadjavascript": true,
"loadimages": false,
"timeout": 30,
"viewport": {
"width": 1280,
"height": 600
}
}
Wait after page load
The waitafterpageload object is optional and indicates if Agenty should wait for some element to be appeared on page or fixed number of seconds before running the fields extractor.
"waitafterpageload": {
"enabled": true,
"type": "SELECTOR",
"timeout": 10,
"selector": ".item"
}
The
waitafterpageloadis enabled by default whenDefaultengine is used, and Agenty will use the 1st field selector of type CSS by default to wait for before running the extraction.
Login
The login object is optional and indicates that, if scraping agent need to login before stating the scraping of pages. The login commands should be added in the data[] array under the login object
"login": {
"enabled": true,
"type": "FORM",
"data": []
}
Logout
The logout object is optional and indicates that, if scraping agent need to logout before completing the job and closing the instance. The logout commands should be added in data[] array under logoutobject
"logout": {
"enabled": true,
"data": []
}
Pagination
The pagination object is optional and indicates the next page button or the hyperlink to click next page in a listing or search page.
"pagination": {
"enabled": true,
"type": "CLICK",
"selector": ".next a",
"maxpages": 5
}
Retry Errors
The failretry object is used to set the retry configuration for HTTP errors. When, the retry option is enabled - Agenty will retry the error requests with HTTP status code 400 or higher until one of these conditions met:
- Request succeed (StatusCode : 2xx)
- Maximum retries completed
- Timed out
"failretry": {
"enabled": true,
"maxtry": 3,
"tryinterval": 2,
"timeout": 60
}
Remember: Agenty automatic retry mechanism will retry the error requests via new proxy server (IP address), when retry option is enabled to improve the overall success rate(If you are on Professional or higher plan, which includes the automatic proxy/IP rotation feature).
Throttling
The throttling feature helps you to add a few seconds of delay, when running a web scraping agent for more than one URL. It’s recommended to use this option for professional data scraping and also the best practice of website scraping to delay between sequential requests. There are 2 types of delay options available to configure the throttling:
- Fixed - The scraping agent will wait exactly
xseconds given insecondsparameter. - Random - The scraping agent will generate a random number between 0 and given value in
secondsto wait, before scraping the next URL in input
"throttling": {
"enabled": false,
"type": null,
"seconds": 0
}
FAQs
How can i have the scraped URL appear in the output?
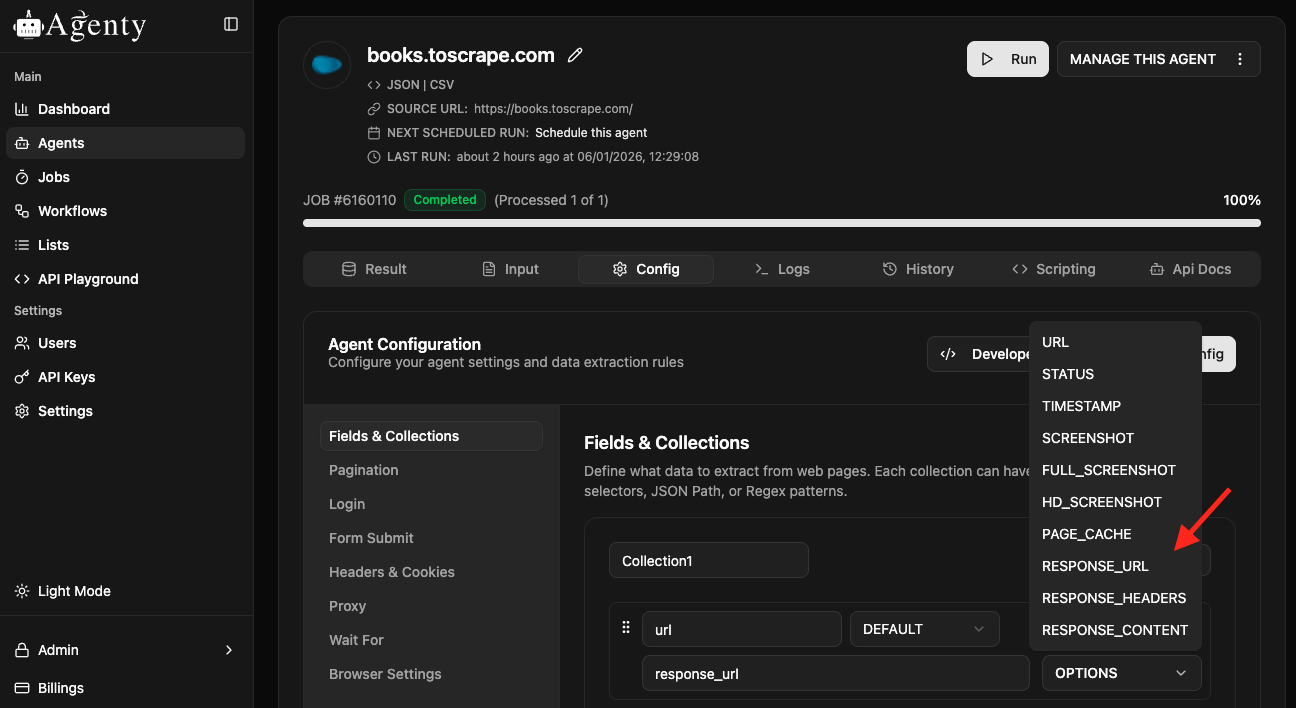
Go to your agent page > Configuration tab > Add a default field with from as REQUEST_URL or RESPONSE_URL in your scraping agent. You may learn more about default fields here
- REQUEST_URL : The request URL is the same as it was in input.
- RESPONSE_URL : The response URL is served by the web server. For example, if your input URL is auto-redirecting to some other URL, the response URL will be the final URL after all the redirections, while the request URL will display the same URL as it was in the input.
Can I use one web scraping agent to scrape many websites?
Yes, there are cases where one agent can also be used for many websites scraping as well, for example:
- Meta Tags Scraping: If you are looking to extract the meta tags (title, description, canonical etc) from websites, which are mainly used for SEO purpose from thousands of websites. You can use the same agent for all the websites because every website has the same structure for meta tags like below
<title>page title here</title>
<meta name="description" content="page description here" />
<link rel="canonical" href="page url here" />
- Structured Data Scraping: Google and most of the other search engine uses the structured data to display instant result on search engine about an organization, product, review, rating and many more and most of the popular websites uses the structured data markup to display the information on their websites to ensure their website is search engine friendly and better rank. So, you can create an agent to extract the structured data and then can use the same agent for many websites which is using the structured data
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Organization",
"url": "http://www.example.com",
"name": "Unlimited Ball Bearings Corp.",
"contactPoint": {
"@type": "ContactPoint",
"telephone": "+1-401-555-1212",
"contactType": "Customer service"
}
}
</script>
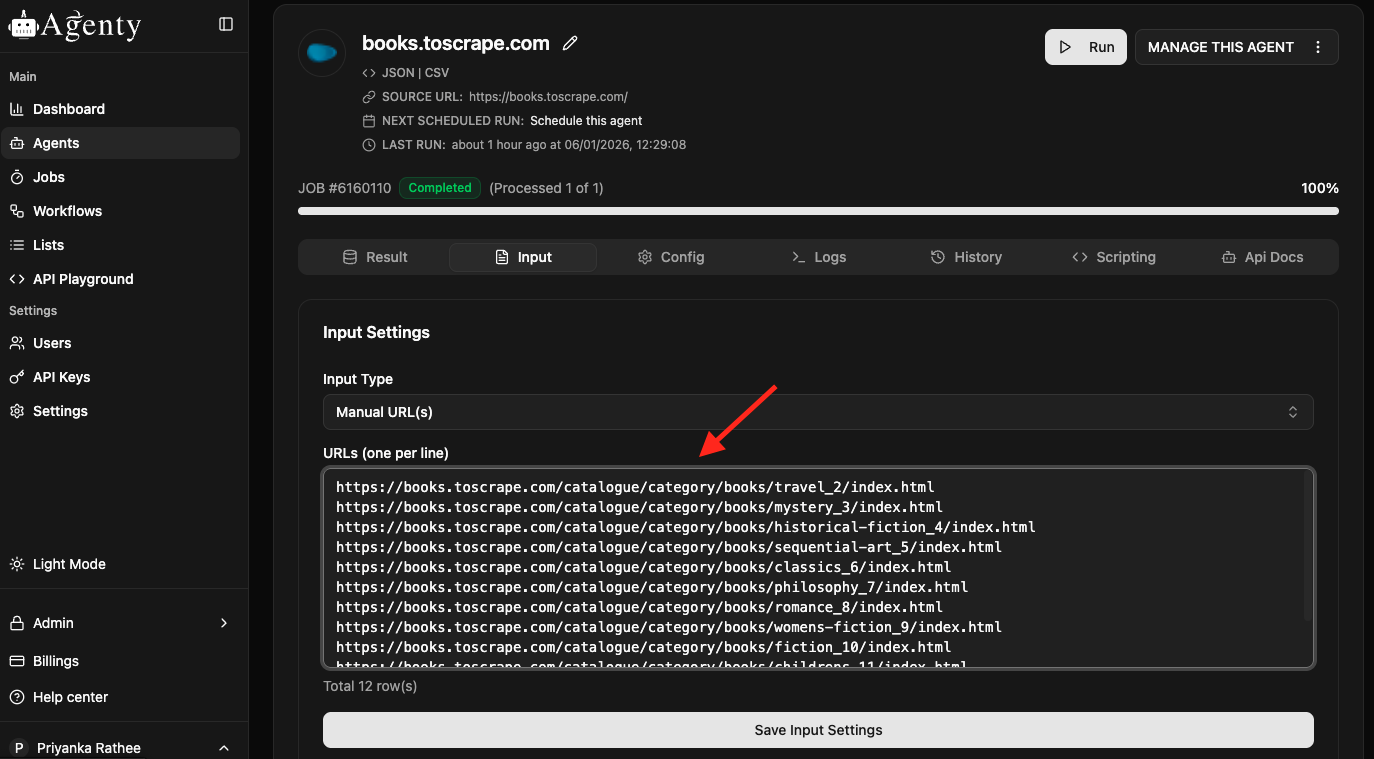
How to do batch crawling when I have the list of URLs?
There are many input types available in scraping agent to pass the URLs. If you have a list of URLs to scrape from any website, follow these steps for batch crawling:
- Go to agent page > then input tab
- Select input as Manual URLs
- Paste your URL list (One URL per line)
- Save the input configuration and Start the agent
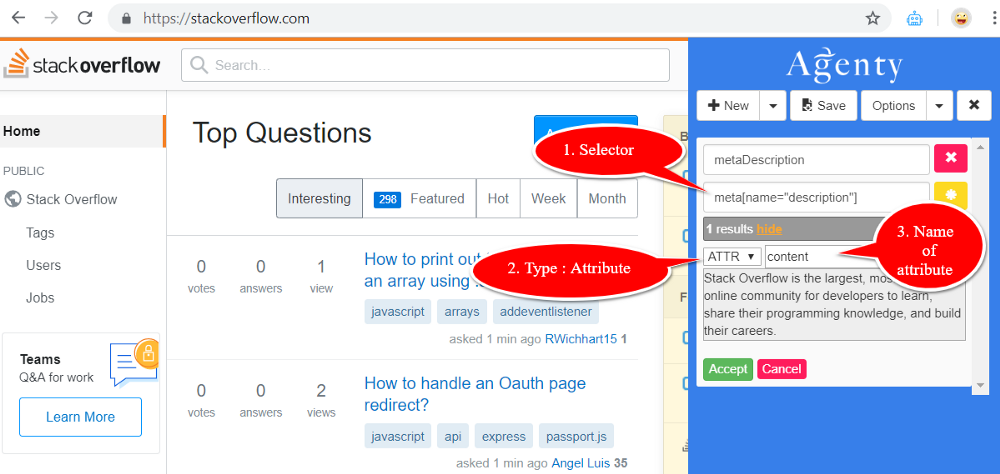
How to scrape meta tags content?
Meta tags scraping is almost same as other elements scraping from HTML, we can use the Agenty Chrome extension (or agent editor) to add a field to scrape any attribute we want from a meta tag. The only difference in scraping meta tags will be that - we’d need to write our CSS selector manually, because meta tags are hidden HTML tags - So, we can’t just point-and-click on them to generate the selector automatically
- Write your selector manually by looking on the HTML source
- Select the
ATTR(attribute) option in extract type - Enter the name of attribute you want to scrape
How can I create a static field to insert custom field values in scraping result?
To add a static field in your web scraping agent - You need to add a field with type : Default then add any default value to set the static value of your choice and save this configuration.
Run the agent now: